
از آنجایی که برنامه های کاربردی امروزی پیچیده تر و توزیع شده تر می شوند، وجود یک سیستم نظارت(Monitoring) و تجزیه و تحلیل قوی برای پیگیری عملکرد، در دسترس بودن و سلامت سیستم بسیار مهم است. یک سیستم مقیاس پذیر توزیع شده معمولاً از چندین مؤلفه تشکیل شده است که برای دستیابی به عملکرد مورد نظر با هم کار می کنند. این مؤلفه ها می توانند بر روی سرورهای مختلف، مراکز داده یا حتی قاره های مختلف اجرا شوند.
یک سیستم مقیاس پذیر توزیع شده دارای چندین بخش مجزا است و هر گونه خرابی در یک جزء می تواند باعث ایجاد اثر آبشاری بر روی اجزای دیگر شود. بنابراین، وجود یک سیستم نظارتی برای شناسایی و هشدار به مدیران سیستم در مورد هر گونه مشکل، ضروری است. نظارت بر سیستم همچنین می تواند آماری در مورد عملکرد سیستم و مصرف منابع ارائه دهد. تجزیه و تحلیل می تواند به شناسایی الگوها، روندها و ناهنجاری ها در رفتار سیستم کمک کند، که می تواند برای بهبود عملکرد کلی و مقیاس پذیری سیستم استفاده شود.
یک سیستم مقیاس پذیر توزیع شده باید با این فرض طراحی شود که اجزا در هر زمانی ممکن است خراب شوند. یک سیستم نظارتی که به طور مداوم سلامت سیستم را بررسی می کند می تواند به شناسایی و اطلاع رسانی سریع این خرابی ها کمک کند. در نتیجه خرابی به حداقل میرسد و تأثیر آن بر کاربران نهایی را کاهش میدهد.
اولین قدم در پیاده سازی یک سیستم نظارت، تعریف معیارهایی است که باید ردیابی شوند. معیارها باید با عملکرد سیستم، در دسترس بودن و استفاده از منابع مرتبط باشند. نمونه هایی از معیارها عبارتند از: زمان پاسخ، نرخ خطا، میزان استفاده از CPU، میزان استفاده از حافظه، تأخیر شبکه و توان عملیاتی. پس از تعریف معیارها، تعیین آستانه هشدار برای هر معیار ضروری است. این آستانه ها باید بر اساس نیازمندی های سیستم باشد و زمانی که سیستم از رفتار مورد انتظار منحرف می شود، هشدارهایی را ایجاد کند.
انتخاب ابزار نظارتی مناسب برای مفید بودن سیستم نظارت بسیار مهم است. ابزارهای نظارتی متعددی در بازار موجود است و هر کدام نقاط قوت و ضعف خود را دارند. برخی از ابزارها برای نظارت بر زیرساخت مناسب تر هستند، در حالی که برخی دیگر برای نظارت در سطح برنامه مناسب تر هستند. در نظارات سیستم باید ابزاری را انتخاب کنید که بتواند تمام اجزای سیستم از جمله زیرساخت، برنامهها و پایگاههای داده را نظارت کند.

ردیابی توزیع شده تکنیکی است که جریان حرکت یک درخواست را در یک سیستم توزیع شده با بخش های مجزا، ردیابی میکند. این نوع ردیابی اجازه می دهد تا مدیران سیستم درک کنند که چگونه درخواست ها توسط اجزای مختلف سیستم پردازش می شود. با بکارگیری از این روش می تواند محل خطا در یک سیستم توزیع شده و همچنین گلوگاه ها(bottlenecks) را شناسایی کرد.
گزارش ها(Log) اطلاعات ارزشمندی در مورد رفتار سیستم ارائه می دهند و می توان از آنها برای شناسایی مسائل و خطاها استفاده کرد. پیادهسازی یک سیستم جمعآوری و تجزیه و تحلیل گزارش میتواند به شناسایی الگوها، روندها و ناهنجاریها در رفتار سیستم کمک کند. همچنین می تواند به شناسایی مسائل امنیتی و حملات احتمالی کمک کند.
تجزیه و تحلیل مبتنی بر یادگیری ماشینی می تواند به شناسایی الگوها، روندها و ناهنجاری های پنهان سیستم کمک کند. مواردی که ممکن است از طریق نظارت انسانی آشکار نشوند. الگوریتمهای یادگیری ماشینی میتوانند از دادههای گذشته بیاموزند و تحلیلی در مورد رفتار سیستم ارائه دهند. از این تجزیه و تحلیل ها می توان برای بهینه سازی عملکرد و مقیاس پذیری سیستم استفاده کرد.
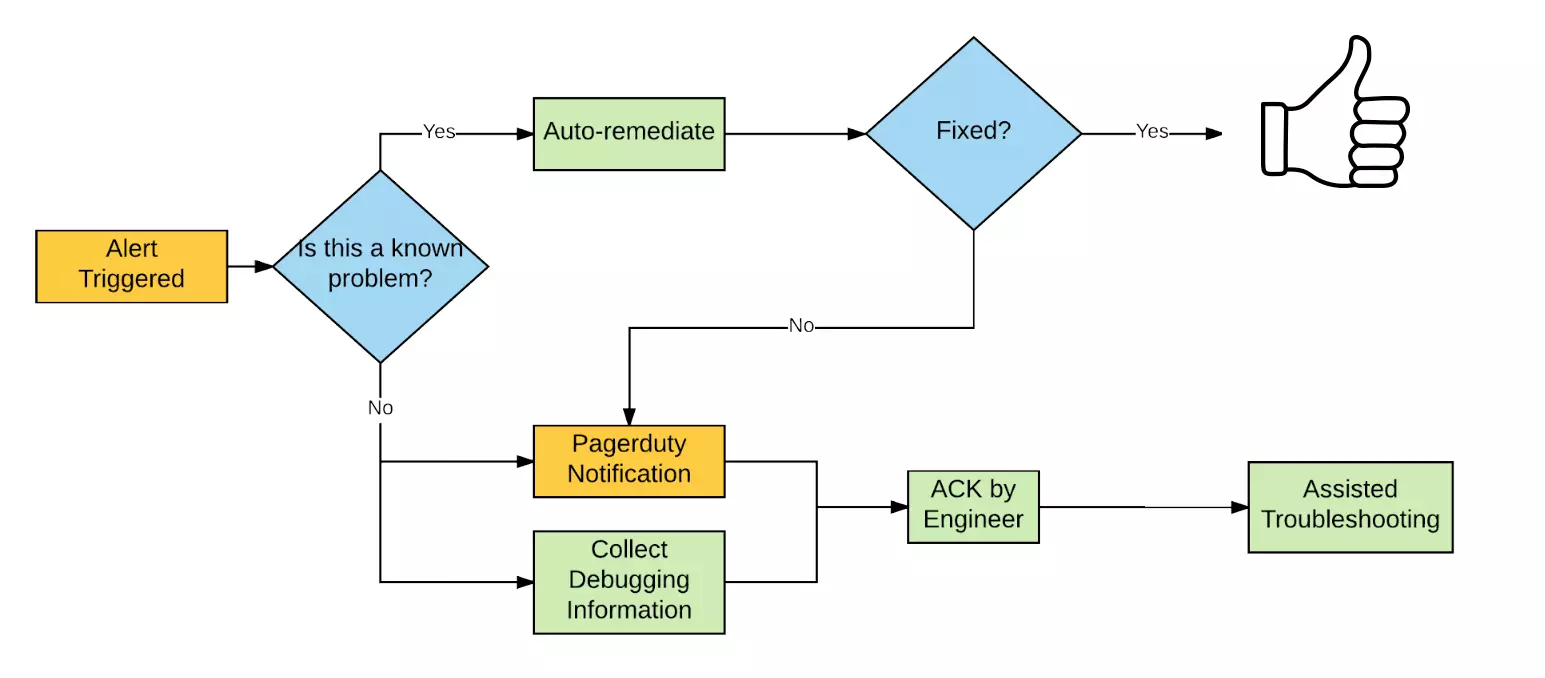
اصلاح خودکار بخشی ضروری از یک سیستم نظارتی است. هنگامی که یک هشدار فعال می شود، سیستم باید به طور خودکار اقدامات اصلاحی را برای رفع مشکل انجام دهد. این اصلاحات میتواند شامل راهاندازی مجدد یک مؤلفه خراب، افزایش یا کاهش منابع یا مسیریابی ترافیک به مؤلفههای سالم باشد.
ابزارهای نظارتی متعددی برای نظارت و تجزیه و تحلیل در یک سیستم مقیاس پذیر توزیع شده موجود است که می توانند بهکارگرفته شوند. در ادامه برخی از ابزارهای محبوب بصورت مختصر معرفی شده اند.
Prometheus: ابزار Prometheus یک سیستم مانیتورینگ منبع باز است که معیارها را از منابع مختلف جمعآوری کرده و در پایگاه داده سری زمانی(time-series database) ذخیره میکند. این ابزار دارای یک زبان پرس و جو قدرتمند است که می تواند برای پرس و جو از معیارها و ایجاد هشدار استفاده شود.
Grafana: ابزار Grafana یک ابزار بصری سازی است که می تواند برای نمایش معیارهای جمع آوری شده توسط Prometheus استفاده شود. از این ابزار میتوان برای ایجاد داشبورد های نظارتی بصری به همراه نمودار های مختلف استفاده کرد. همچنین قابلیت ایجاد هشدار یکی دیگر از ویژگی های این ابزار است.
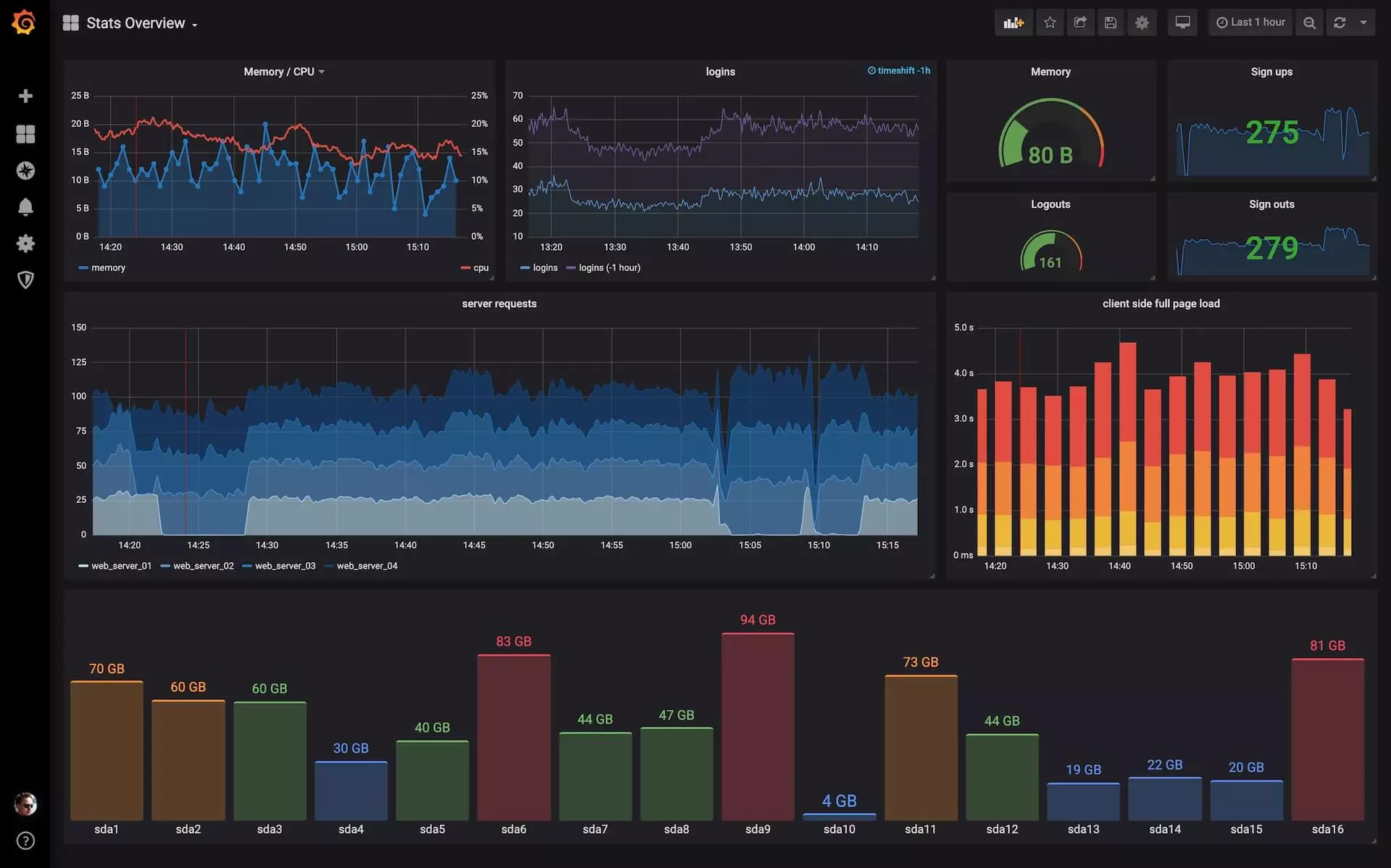
Datadog: پلتفرم Datadog یک پلتفرم نظارت و تجزیه و تحلیل ابری غیر رایگان است که از سرویس های ارائه دهندگان خدمات ابری همچون AWS، Azure، Google Cloud و... پشتیبانی می کند. این پلتفرم نظارت، هشدار و تجزیه و تحلیل در لحظه را با کیفیت بالا ارائه می دهد و می تواند برای نظارت بر عملکرد و سلامت سیستم های توزیع شده استفاده شود.
New Relic: پلتفرم New Relic یک پلتفرم نظارت و تجزیه و تحلیل ابری مشابه Datadog است که نظارت، هشدار و تجزیه و تحلیل در لحظه را ارائه می دهد. این پلفترم از چندین زبان برنامه نویسی پشتیبانی می کند و می توان از آن برای نظارت بر عملکرد سیستم های توزیع شده استفاده کرد.
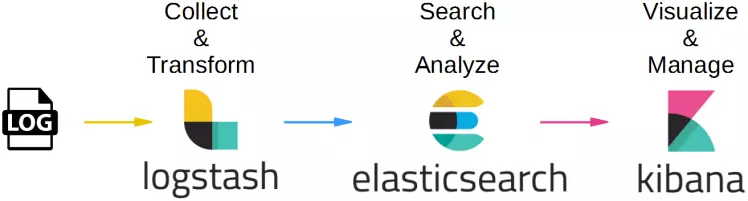
Elastic Stack: پلتفرم Elastic Stack یک مجموعه ابزار منبع باز است که چندین ابزار برای نظارت، جمع آوری گزارش و تجزیه و تحلیل فراهم می کند. این ابزار ها شامل Elasticsearch، Logstash و Kibana هستند که میتوانند در کنار هم برای جمعآوری، ذخیره و تجزیه و تحلیل گزارشها و معیارها استفاده شوند.
Zabbix: ابزار Zabbix یک ابزار نظارت منبع باز برای زیرساخت است که قادر به نظارت بر سرورها، برنامه ها، شبکه ها و سرویس ها است. این ابزار دارای امکانات هشدار، بصری سازی و گزارش در در لحظه از منابع را با معماری انعطاف پذیر و مقیاس پذیر ارائه می دهد. ابزار Zabbix کاربر پسند است و به طور گسترده در سازمان های کوچک و بزرگ استفاده می شود.
نظارت و تجزیه و تحلیل اجزای ضروری یک سیستم مقیاس پذیر توزیع شده هستند. آنها اطلاعاتی در مورد عملکرد، در دسترس بودن و سلامت سیستم ارائه می دهند و به شناسایی مسائل قبل از تأثیرگذاری بر کاربران نهایی کمک می کنند. پیادهسازی یک سیستم نظارتی مستلزم تعریف معیارهای مربوطه و آستانه هشدار، انتخاب ابزار نظارتی مناسب، جمعآوری و تجزیه و تحلیل گزارش و اصلاح خودکار است. با پیاده سازی یک سیستم نظارتی صحیح، مدیران سیستم می توانند اطمینان حاصل کنند که سیستم های مقیاس پذیر و توزیع شده آنها همیشه در دسترس، کارآمد و عاری از خطا هستند.

من محمدرضا باباخانی هستم، توسعه دهنده نرم افزار. در اینجا تجربیات، نظرات و پیشنهادات خودم رو درباره تکنولوژی مینویسم. امیدوارم مطالبی که مینویسم بدردتون بخوره.



ثبت دیدگاه